RNA to Protein Translation in PERL
In PERL programming, an RNA sequence can be translated to a protein sequence by substituting equivalent amino acid characters to triplet characters of RNA. This method has followed to find six reading frames (three in the forward direction, and three in the reverse direction). In this program, I have used the associative array (also known as a hash array) to associate triplet characters with amino acid characters.
The associate array corresponding to codon table is arranged to 20 amino acid character. The triplet codon table is shown below:
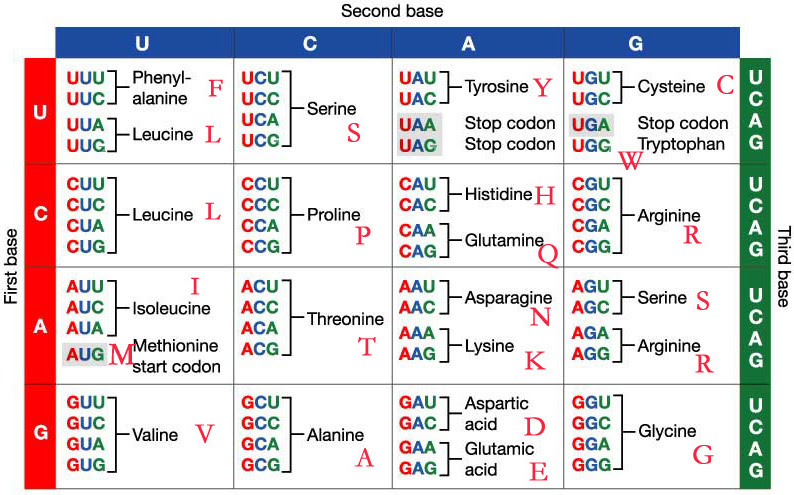
Source Code:
print "Enter the RNA sequence: ";
$rna = <>;
chomp($rna);
$rna =~s/[^acgu]//ig;
my $rna = uc($rna);
my(%genetic_code) = (
'UCA' => 'S', # Serine
'UCC' => 'S', # Serine
'UCG' => 'S', # Serine
'UCU' => 'S', # Serine
'UUC' => 'F', # Phenylalanine
'UUU' => 'F', # Phenylalanine
'UUA' => 'L', # Leucine
'UUG' => 'L', # Leucine
'UAC' => 'Y', # Tyrosine
'UAU' => 'Y', # Tyrosine
'UAA' => '_', # Stop
'UAG' => '_', # Stop
'UGC' => 'C', # Cysteine
'UGU' => 'C', # Cysteine
'UGA' => '_', # Stop
'UGG' => 'W', # Tryptophan
'CUA' => 'L', # Leucine
'CUC' => 'L', # Leucine
'CUG' => 'L', # Leucine
'CUU' => 'L', # Leucine
'CCA' => 'P', # Proline
'CAU' => 'H', # Histidine
'CAA' => 'Q', # Glutamine
'CAG' => 'Q', # Glutamine
'CGA' => 'R', # Arginine
'CGC' => 'R', # Arginine
'CGG' => 'R', # Arginine
'CGU' => 'R', # Arginine
'AUA' => 'I', # Isoleucine
'AUC' => 'I', # Isoleucine
'AUU' => 'I', # Isoleucine
'AUG' => 'M', # Methionine
'ACA' => 'T', # Threonine
'ACC' => 'T', # Threonine
'ACG' => 'T', # Threonine
'ACU' => 'T', # Threonine
'AAC' => 'N', # Asparagine
'AAU' => 'N', # Asparagine
'AAA' => 'K', # Lysine
'AAG' => 'K', # Lysine
'AGC' => 'S', # Serine
'AGU' => 'S', # Serine
'AGA' => 'R', # Arginine
'AGG' => 'R', # Arginine
'CCC' => 'P', # Proline
'CCG' => 'P', # Proline
'CCU' => 'P', # Proline
'CAC' => 'H', # Histidine
'GUA' => 'V', # Valine
'GUC' => 'V', # Valine
'GUG' => 'V', # Valine
'GUU' => 'V', # Valine
'GCA' => 'A', # Alanine
'GCC' => 'A', # Alanine
'GCG' => 'A', # Alanine
'GCU' => 'A', # Alanine
'GAC' => 'D', # Aspartic Acid
'GAU' => 'D', # Aspartic Acid
'GAA' => 'E', # Glutamic Acid
'GAG' => 'E', # Glutamic Acid
'GGA' => 'G', # Glycine
'GGC' => 'G', # Glycine
'GGG' => 'G', # Glycine
'GGU' => 'G' # Glycine
);
my ($protein) = "";
for(my $i=0;$i<length($rna)-2;$i+=3)
{
$codon = substr($rna,$i,3);
$protein .= $genetic_code{$codon};
}
print "Translated protein sequence is $protein";
<>;This program can also used for six reading frame, by changing the three character shift in forward and reverse of the RNA sequence.



(.=) what is the function of this operator? can you please explain
ReplyDeleteIt is the combination of concatenation and assignment operator. For example, $protein .= $genetic_code{$codon}; is equivalent to $protein = $protein . $genetic_code{$codon};
Deletethank you very much sir:)
Deletethank you very much sir:)
DeleteBest wishes...
DeleteIs it feasible to have spaces between the amino acids when they are printed ? I would really appreciate it, if you give me a response
ReplyDeleteHave a nice day
It is possible to split the amino acid sequence into words and/or lines, similar to NCBI BLAST sequence alignment output. Just add additional lines at end of the program to print spaces between the amino acids.
DeleteFor example,
$substr_eq = length($protein) / 50;
$substr_rem = length($protein) % 50;
if ($substr_rem == 0) $substr_eq--;
print "Translated Protein Sequence: \n\n\t";
for ($i = 0; $i < $substr_eq + 1; $i++) {
for ($j = $i * 50; $j < length($protein) && $j < ($i+1) * 50; $j += 1) {
if (($j + 1) % 10 == 0) {
print $protein[$j] . " ";
} else {
print $protein[$j];
}
}
print "\n\t";
}
Thank you for the example script. I am not sure about the meaning of my $rna =~s/[^acgu]//ig
ReplyDeleteThe meaning of the ig flags is not easy to look up in the documentation. Could you elaborate?
g - globally match the pattern repeatedly in the string. For example, "ATCGAAG" will match "A" as "A---AA-" under /g.
Deletei - do case-insensitive pattern matching. For example, "A" will match "a" under /i.
Reference: https://perldoc.perl.org/perlre